
How not to use JavaScript for SEO?
The use of JavaScript in modern web development and design is inevitable. JavaScript improves interactivity and is responsible for visually engaging websites. However, if a website heavily relies on it, and it is not optimised so that Google can crawl and index it in an optimal way, having a modern looking website will be worth nothing.
If a site is not indexed in Google or any other search engine, it surely won’t get traffic. And, in order the site to be indexed, the content should firstly be visible for search engines and crawlable.
So, what we should avoid and how can we use JavaScript having SEO in mind, so that our site is interactive and modern, while at the same time crawlable and indexable?
- Don’t rely on Client Side Rendering for JavaScript
- Don’t use JavaScript to serve different content versions
- Don’t Block JavaScript, CSS or Image Resources
- Don’t Use (Fragmented URLs) in Pagination
- Don’t Forget to Use
<a>HTML Element With anhrefAttribute for Linking
Common JavaScript SEO Mistakes to Avoid
Don’t rely on Client Side Rendering for JavaScript
Your site can be entirely or only partially reliant on JavaScript. However, even if not the entire website is built with JavaScript, I came across situations where the Main Content or important resources are dynamically injected and heavily reliant on JavaScript execution.
In most of these instances, JavaScript is client-side rendered, thus, is only visible for the search engines after being rendered in the browser, which is not a good practice. This means that the Main Content is not visible for search engines, and mostly depends on user interaction for this. Besides, client-side rendering impacts the page loading times as it takes longer to render the JavaScript content in the browser.
How to inspect this?
You can inspect whether the site relies on client-side rendering by looking at the HTML code of the page. Usually, heavy reliant on client-rendered JavaScript pages have very little code in the raw HTML.
Tool: View Rendered Source
Another way to inspect the code is by running a crawl in Screaming Frog and inspecting the rendered code vs raw HTML. In order to do this, you must ensure that you enable JavaScript rendering (Configuration > Spider > Rendering). In addition, enable the crawler to store Rendered HTML (Crawl > Extraction).
How to fix?
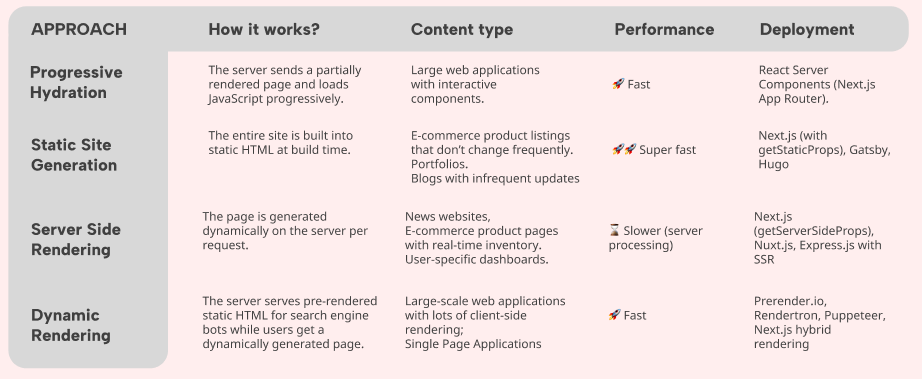
Turn away from the client-side rendering and opt for a different rendering option, such as server-side rendering, dynamic rendering or static site generation. Which one of these is most suitable, will depend on multiple factors, in particular, how often your content is updated. However, any of these is better than client-side rendering.
How to know which solution to use?
This will depend on what is the easiest deployment option having in mind the current site setup, but also on how often does your content update. Less frequent content updates should go for Static Site Generation, as this is the fastest option.
Don’t use JavaScript to serve different content versions
JavaScript should not be used to serve different content versions to users and search engines. For example, if you feature content in Spanish in the raw HTML on the static version of the URL, do not rely on JavaScript to inject the content in English to this same URL, as only one version will be visible to search engines.
In this example, JavaScript is altering the content, thus we have different content featured on the same URL, one version being only visible to the user (English), while the search engines are not able to see it.
The only content present in the raw HTML is Spanish, thus this is the only content search engines will see.

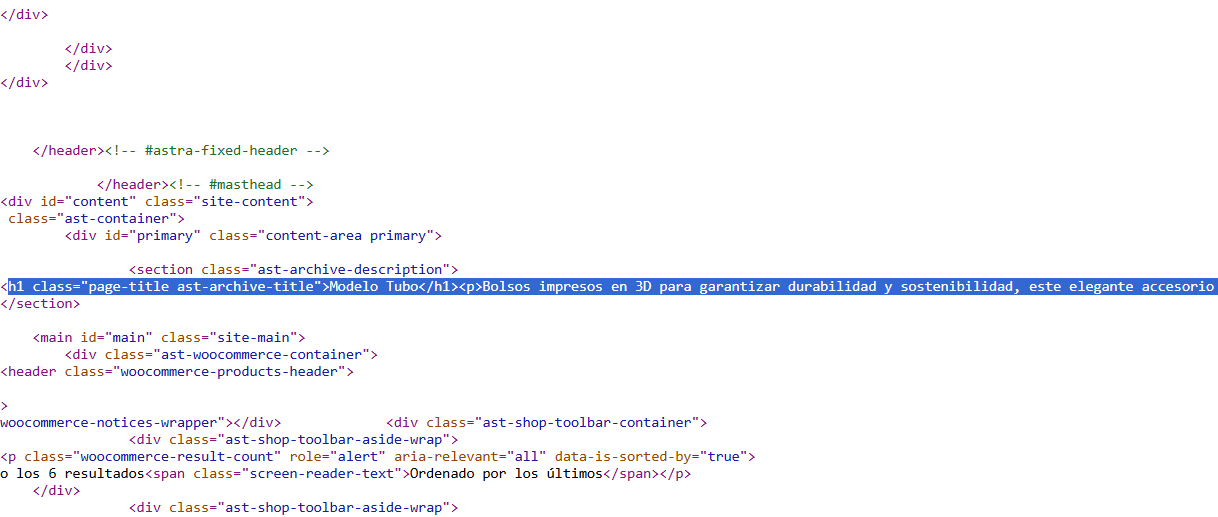
This can be interpreted as cloaking, because we are showing different content to users and search engines. Cloaking is black-hat SEO and can result in penalties!
Moreover, this set-up generally has a negative impact on the performance because only one version of the content exists for search engines. If we want the English content to rank and get traffic, this set-up results in complete opposite, as the content is not being crawled or indexed.
How to inspect and detect this issue?
Start with inspecting the indexation of the pages. If there are issues with Google not being able to see your content, this will be reflected on the indexation, as these pages won’t be indexed.
Tools: Screaming Frog, Google Search Console, SERP
Check and compare raw and rendered HTML code. Is the content visible at all? What is the content present in the HTML code?
How to fix?
Create unique URLs for each language version with unique content in the raw HTML. In this particular case, create a unique URL path for English version, where the content will be found in the raw HTML. On the other site, the Spanish version should be served in a dedicated site section for this particular language. This way, there will be two unique URLs, featuring content in the raw HTML for each audience.
Don’t Block JavaScript, CSS or Image Resources
Blocking crawlers from accessing JavaScript or resources such as CSS with the robots.txt disallow directive is such a common error! I cannot highlight enough how important it is that search engines are able to fetch and crawl these resources, so they can render them correctly.
If internal JavaScript (and CSS) or other important resources, such as images, are blocked, this means that search engines cannot crawl and render them, meaning that any content on the page depending on these resources won’t be visible and as a result, it won’t be indexed either.
This happens so often! For example, MANGO shop website robots.txt is blocking Google from accessing and crawling images. Thus, Google is not able to see any of the images on their page (see below).
For example, Mango blocks their images from being crawled by search engines. I checked their robots.txt file and identified the directive blocking search engines from accessing these resources. Hopefully, they will see this post and fix the issue! 😄
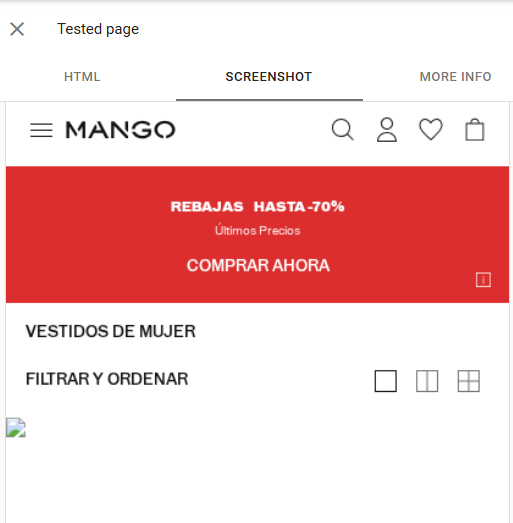
The image above depicts how Google currently sees this page, and, as we can see, the image is not accessible.
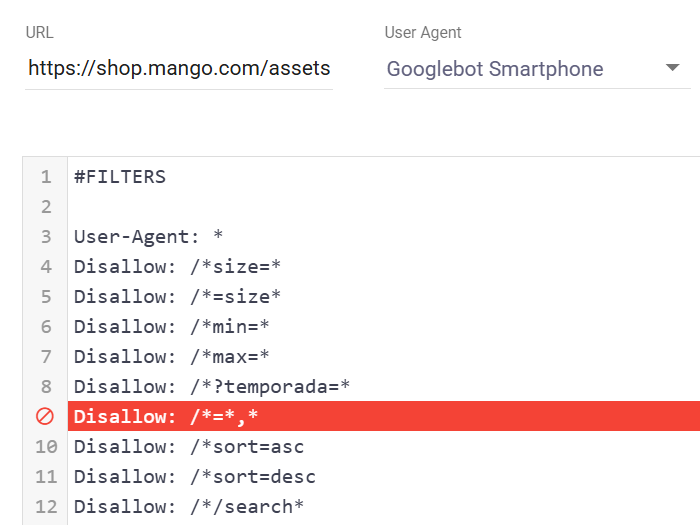
There is a directive in their robots.txt (see below) that is blocking Google from crawling these resources. For this reason, when creating disallow directives in your robots.txt file, you should always ensure that important site sections or resources such as JavaScript, CSS or images are enabled for being crawled.
Tool: Robots.txt Validator
How to fix?
Ensure that you check your robots.txt file and remove any directive blocking search engines form crawling JavaScript (and CSS) resources.
Don’t Use # (Fragmented URLs) in Pagination
I came across this practice more than once. Using fragmented URLs (#) for pagination or loading any kind of content we want to index is bad practice. Simple reason for this is the fact that Google does not recognize any content that would appear after the # in the URL.
URL fragments can be used to anchor to different sections on the page for example, however, not to introduce new content, as this content for Google won’t exist.
How to fix?
When it comes to pagination, as ideally we want each page in the paginated sequence to be indexed, this means that pagination introduced with fragments would not be an option, and parameters should be used instead. See Google’s documentation on Pagination Best Practices.
When to use # URLs then?
Fragmented (#) URLs can be used for sorting, filtering and faceted navigation, as well as for anchoring to different sections on one page.
Don’t Forget to Use <a> HTML Element With an href Attribute for Linking
Links will be crawlable for Google if you rely on JavaScript to insert them into a page dynamically only if you use any of the following HTML markup:
<a href=“https://example.com”>
<a href=”/products/category/shoes”>
<a href=”./products/category/shoes”>
<a href=”/products/category/shoes” onclick=“javascript:goTo(‘shoes’)”>
<a href=”/products/category/shoes” class=“pretty”>
Google generally can only crawl links within the <a> HTML element with an href attribute. Thus, if links are included in the content in any other way, they won’t be crawled which will lead to indexation issues.
Don’t Rely on JavaScript for the Links in the Main Navigation
The main navigation is super important for crawling and indexing. All the most important site links are found in the main navigation, signaling to Google that these are the pages we want to be found in the SERP.
If our links in the main navigation are only visible after JavaScript is client side rendered, this will result in search engines not seeing the links until the code is rendered in the browser. This means that the links in the main navigation will basically be invisible for search engines.
How to fix?
The links in the main navigation should always be present in the raw HTML. This is the first part of the site Google will crawl, and, apart from navigational links, other important elements, such as language selector can be found in the main navigation.
Having in mind how important the navigation is, the links here should always be present in the raw HTML in the <a> HTML element with an href attribute.
SEO Friendly JavaScript Use Overview
✔️ Move away from client-side rendering to server side rendering or any other more SEO friendly method.
✔️ Ensure that each page has a unique URL path with unique content featured in the raw HTML, avoid the use JavaScript for serving different content versions.
✔️ Don’t block JavaScript, CSS or images from being crawled. Ensure that robots.txt does not block any of these important resources.
✔️ Don’t use # URLs in the internal linking or the pagination on the site, as fragmented URLs are not recognized by Google as unique.
✔️ Use <a> HTML element with an href attribute for internal linking, in particular in the main navigation.
Leave a Reply